Git merge vs git rebase – why you should avoid using Git merge to update your branches?
Git is a the most popular version control system in the software engineering world. Its popularity grown even bigger with the raise of Github, Gitlab, Bitbucket and similar tools. When you think about software development Git is a crucial part of it, you just can’t live without it if you’re doing it professionally.
Background
Imagine you’re working on some big feature that requires a lot of time to implement it properly. In the meantime your team members are developing their own tasks. They get reviewed and merged to to the branch: master, main, develop - you name it (I'm going to refer to it as a source branch later in the text).
At some point you realize that it would be good to update your working branch with the latest changes from the source branch. It can be tempting to do it by either running git merge <source-branch-name> or by clicking on:
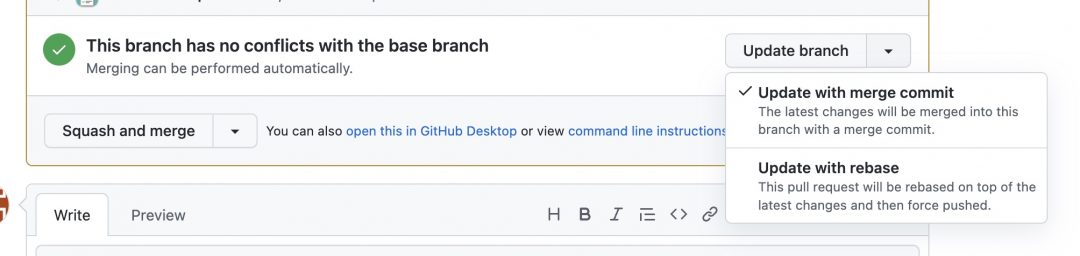
Update with merge commit option. After doing it the list of commits is increased by a number of merge commits and it can look like the following:
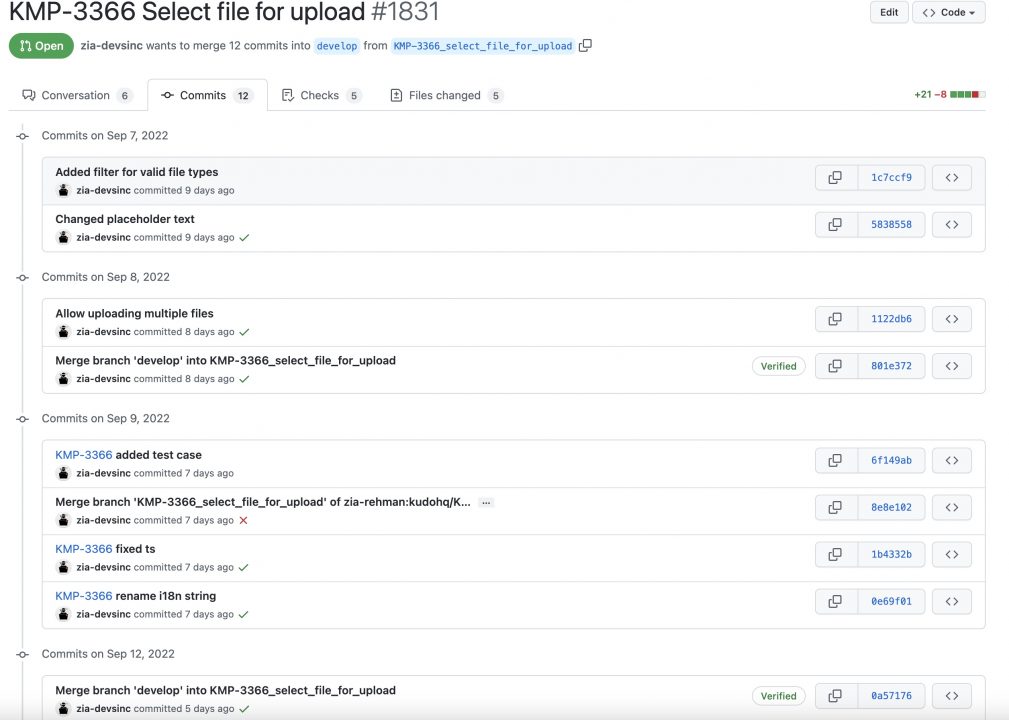
Notice, there are commits starting with Merge branch ‘develop’ into … those are the merge commits, but if you take a look at the branch history on Git you would see something like this:
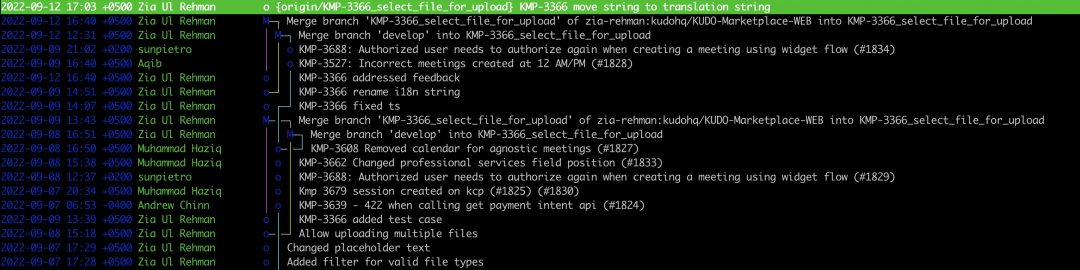
In the Github UI there are 12 commits, but when you’re looking into the Git history you can see there are 19 commits in total.
Git merge is a bad idea
You might be wondering what’s the problem there? IMO, it’s bad because it messes up your work with someone else’s work. Mixing commits leads to confusion when trying to find a specific commit that introduced a specific bug or trying to squash all your commits into one with git rebase -i HEAD~<number-of-your-commits>.
In general, your work should be always on top of the source branch commits so you can easily find out what does your work contain and, what’s more important, you can have a flat commits history in your branch. In the last picture there are 3 levels of commits caused by using git merge. Which can be problematic to read sometimes. More nesting levels mean more complex graphs to read and to understand the history of changes.
Using git rebase will help you:
- To have a clear list of changes in your repository. You’ll know what change is an effect of another.
- To have a linear history of changes. No nested levels of commits making it difficult to read.
- To debug your code easier with
git bisect. This command is really cool to find the exact commit that broke the code. With that you can mark which commits are good and which are broken. You can read more about it here: https://git-scm.com/docs/git-bisect
What can you do instead?
Instead of doing git merge <source-branch-name> you can do git rebase <source-branch-name>. By doing so you can make sure that all your changes will be visible on top of the list of changes.
Sometimes, while doing so, there might be conflicts. Usually, they are not difficult to solve. However if you don’t update your working branch frequently with the latest changes from your source branch, then you might get into a difficult situation when resolving conflicts gets really complicated:
- You have to understand the most recent changes,
- You must analyze if there was some code refactoring done by some of your teammates that is affecting your code: “Maybe the file you’ve worked on doesn’t exist anymore?”
In such situations I can suggest doing one of 2 things:
- Combine your work into one commit and rebase
- Or combine your work into one commit and apply your commit on a fresh branch
I’m going to describe all of the above strategies in the following sections.
Squash and rebase
- Squash all your work into one commit, unless you really want to have a specific commit visible in your PR (in such situation maybe you should create another PR with that change only?)
- Run
git rebase -i HEAD~<number-of-commits>to do the squash in the CLI, - Once you have all your commits squashed into one do run the
git rebase ...command once again. - Resolve your conflicts once and for always, because you have a clear overview of all your changes.
Squash and start fresh
This specific strategy is useful when having so many conflicts that it’s really difficult to solve them all properly.
- Squash all your commits into one commit,
- Create a copy of your current branch -
git checkout -b <copy-current-branch-name>, - Go back to the original feature branch -
git checkout -, - Hard reset the content of the branch -
git reset --hard origin/<source-branch>. It will overwrite everything in your branch. -
Cherry-pick your commit from the branch copy -
git cherry-pick <commit-hash>. If you don’t know where to find the commit hash then you have to type ingit logcommand and the hash will be visible in the line with commit text. The random set of letters and numbers is the hash you’re looking for.
The final
Once you follow any of those conflicts resolving strategies or after just rebasing your changes you need to force push your changes to the remote repository - git push --force-with-lease. If you’re the only one working on a specific branch, then you don’t have to worry about anything, but if there are several people working on the same branch then the communication is the key. You must let others know that you’re going to force pushing changes to a remote repository. Make everyone involved aware that you’re going to overwrite the existing commits history and ask them to update their local copies as soon as possible to avoid even more difficult conflicts to solve in the future.
Sometimes it’s not that bad idea
So far I’ve written a lot about why rebasing changes is great:
- Having a linear history of changes,
- Having a clear overview of things that matter feature-wise,
- Easier code debugging with
git bisectfunctionality.
But there are also situations where git merge is not that bad and it’s necessary. The situations like:
- Merging pull requests. Obviously you want to see the merging point when you’re new code joined the stable codebase. Before that you must squash all your commits in the feature branch. What the team cares is just your final version of code. All the development/work-in-progress commits don’t matter at the end.
- Merging release branches to the branch where you do the release from, a.k.a production branch. You want to see the history of features changes there. Otherwise the only things you would see are commits like Release 1.10.0 and Release 1.10.0 which are not very informative. You can use tags for tagging specific versions.
Summary
I’m a great fan of linear history in Git, because it helps reasoning what are the changes made during the time being and that makes it easier to debug the codebase in order to find a specific commit that broke a functionality and to develop a proper fix for the issue found.
Following the suggestions in this article helps keeping your codebase healthy and maintainable in the long term, which is great for the developer experience.